Coordinate Transforms in iOS using Swift, Part 0: The Problems
There should be a confessional group for people struggling with coordinate transforms in iOS.
“Hi, my name is Gary, and I get flustered figuring out coordinate transforms in iOS.”
“Hi, Gary!” the crowd replies. Some smile. Some grimace, reminded of their own struggles.
Maybe we’re a small crowd, but you know there are programmers out there trying to find info about image coordinate systems on developer.apple.com, digging through StackOverflow posts, and looking for a straightforward answer to the question “Which way is up?”
Where is that one clear diagram that explains all the coordinate systems for my project? Am I missing some documentation referenced by more experienced iOS developers, or do we all figure out this puzzle on our own?
And if I’ve already spent years working with coordinate frames and matrix math in 2D and 3D, why are image coordinates in iOS still a pain?
This is the zeroth post in a multi-part series. Dealing with coordinate systems is a multi-part problem. In this post I’ll suggest that our problems extend beyond just the math, and that identifying the non-math problems helps lead to a solution that is easy to learn and remember. The math and sample code will follow in the next blog post.
Problems Learning Apple’s 2D Coordinate Systems
If you stumbled onto this post, maybe you’re already familiar with at least some of Apple’s coordinate systems. Perhaps you haven’t yet encountered issues such as the the need (?) of the Vision framework’s OCR engine to have an image oriented as UIImage.Orientation.up. Or maybe you know much more than I do about the ins and outs of coordinate systems in UIView, Core Graphics, Vision, and other frameworks.
When we try to figure out coordinate systems in a framework like Apple’s, we’re doing more than just implementing math in code. We’re developers and engineers who write, deliver, support, maintain, and extend software. Multiple types of work means multiple problems to solve.
To understand why puzzling through coordinate systems is hard, consider some of what confronts us:
- Definitions to Learn. We need to find Apple’s documented conventions for various coordinate systems.
- Relevance of Documentation. Finding Apple documentation that is up to date, correct, and cross-referenced can be tricky. As someone relatively new to iOS development, how do I know whether an archived web page about Quartz2D is still relevant to Core Graphics? Maybe the StackOverflow post I found is the best documentation available.
- Understandability. We can find documentation but have difficulty understanding it. The documentation may not be well written and/or we may find the math difficult. It’s okay to admit you don’t understand!
- The Elusive, Possibly Mythical Holy Grail. Does Apple have an official documentation page or blog post with a graphic explaining how all the coordinate systems relate to one another? I’ve yet to find such a graphic. Though I can imagine it existing, maybe the graphic wouldn’t have the magical healing properties I hope for, and to search for it is to choose poorly how to spend my time.
- Different Conventions. The APIs of Apple frameworks follow different conventions. To me, the matrix types and operations in simd make sense. CGAffineTransform from Core Graphics is less intuitive to me. Your mathage may vary.
- Brain Strain. It takes effort to understand and remember arbitrary definitions: where origins are, where the +x and +y axes point, whether we’re working in proportional coordinate systems, whether matrices should be read row by row or column by column, and so on.
- The Multitudes. Depending on the number of frameworks our app(s) use, we may need to deal with half a dozen coordinate systems or more. That may not seem like many, but each recall of the relationship between coordinate systems can be a little energy-draining moment.
Coordinate Systems from some Apple Frameworks
Core Graphics (CG) coordinates define the origin at bottom left of an image, with +X pointing to the right and +Y pointing up. Hey, that’s just like I learned 2D coordinates in school! Apparently the CG coordinate system traces back to Quartz2D, though I was hoping not to have to read a novel about the history of Apple software development just to find a single graphic about a coordinate system. (Maybe you were hoping these blog posts would provide code and skip the attempts at humor.)
For UIView subclasses, the origin is defined at top left, with +X to the right and +Y down. That’s the convention for image processing and (many) 2D computer graphics libraries, and happens to be familiar to me. I empathize with those for whom having +Y point downward is weird. Let’s acknowledge that with UI coordinates we’ve introduced a second coordinate system that may or may not be easy for us to remember.
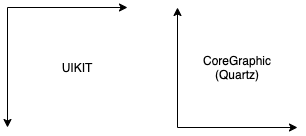
We’ll skip over child UIView instances having their own coordinate systems, and also the scaling transforms to convert from UIImage to, say, a UIView graphics layer. Sigh.
Let’s move on to vision coordinates. They have a range normalized from 0.0 to 1.0 in X and Y. Normalized coordinates are independent of screen resolution. Even if length and width of an image are different, X and Y are each mapped to the range 0.0 to 1.0. There’s a good reason for using normalized (proportional) coordinates, but now we have yet another convention to remember. But hey, at least vision coordinates share an origin with CG coordinates, right? To quote the Vision framework documentation: “Vision uses a normalized coordinate space from 0.0 to 1.0 with lower left origin.”
Except when the origin isn’t at the lower left. When I wrote code to find the locations of QR Codes (2D barcodes), the coordinates were reported in normalized coordinates. However, the coordinates only made sense for an origin at the top right of my screen with the phone in portrait mode, with +X pointed down and +Y to the left. I think these are vision coordinates for processing happening in a CGImage, but . . . maybe not? This confusion is what prompted me to start this series of posts.
And oh yes, there’s device orientation to consider. If the phone rotates from portrait to landscape orientation, or flips upside down, then we’re dealing with the glories of UIImage.Orientation. Maybe you’re working with CGImage from Core Graphics and UIImage from UI Kit, and you have code to transform to and from different device orientations. But maybe the code doesn’t always work, or doesn’t quite make sense to you, and you don’t relish rewriting it and figuring out the necessary translations and rotations again.
From the Vision framework we have OCR that only seems to work well for UIImage.Orientation.up, even if my phone is in portrait mode and should “know” that the current orientation is UIImage.Orientation.right. Apparently we need to forcibly set the orientation to .up to get good results for OCR from the Vision framework. This hack eliminated an aggravating bug for me, but now I have one more thing to document and remember. In portrait mode the orientation is .right by default, but for OCR it must be .up, which means that for OCR a UIImage and its CGImage have the same coordinate system. Which is . . . uh . . .
And so it goes.
Given Apple’s long history, it’s unsurprising they would have multiple frameworks with different conventions borrowed from different fields. People working in graphics, image processing, and machine learning will expect to work with the conventions of their fields. But as app developers, we may straddle multiple such fields, and that means keeping multiple conventions straight.
Goals
Now that we’ve expressed some of the problems, we can set goals for a solution. We’ll address both the technical problems of finding transforms, and also address the mental resources necessary to understand, implement, and remember the solution.
- Definition (singular). Choose just one method of finding transforms from one coordinate system to another. Start with a single convention to which we relate all coordinate systems.
- Simplicity. Reduce complexity by reducing or even eliminating the need to think about rotations, flips, mirroring, normalized coordinates, and so on.
- Documentation. Ensure relatively little documentation is required. Whatever documentation is needed should exist in two places: online here on Medium, and also in the sample code.
- Understandability. Break the code up into pieces that are individually easy to understand for people of varying levels of skill and interest in math.
- Familiarity. Present a technique that relies on math and code most likely to be familiar to people who need it.
- Memorability. Provided just the name of the technique, and a bit of experience running the sample code in an XCode playground, and one should be able to reproduce the technique from scratch even if the documentation and the code go missing.
In the Next Post: The “L Triangle” Technique
In the next post I’ll provide the approach that I believe achieves all these goals. After reading that post, the name “L Triangle” should be enough for you to reproduce the technique from scratch.
